
It’s come to the forefront again as more than a few services that power WordPress sites specifically have experienced some downtime in the last week.
As Jason Cohen from WP Engine rightly states, 100% uptime is “perfection unattainable”:
Nobody wants downtime, and customers who are paying for a hosting solution have a right to ask and be informed about a company’s history of downtime.
In particular, people want to know who has the least uptime, or if there is a company that has achieved 100% uptime. The reality is that 100% uptime, while the goal that every company sets its sights on, is a perfection unattainable.
Specifically, ServerBeach San Antonio, Page.ly, Zippykid, and WordPress VIP all had a few blips. Although all of them admitted publicly their challenges and what they are going to do to remedy it, only one of those four services has a real-time uptime dashboard:
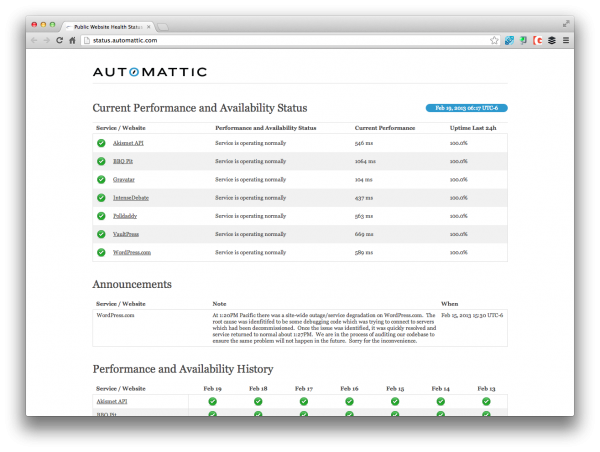
As you can see, Automattic has performance mapped out on their status site. This is not unlike what many other hosting services have, such as Amazon.com and their AWS solution:

The first question is simple: As more and more players jump into the WordPress Managed Hosting scene, should there be greater accountability and transparency around their hosting uptimes?
The second question is a much more technical one in nature and one that was succinctly brought to the surface by Brian Krogsgard in response to Cohen’s post about uptime:
I think the fatigue a lot of people feel (in general, not WP Engine specific) is that the reality of downtime doesn’t often mesh with the sales pitch.
Hosts sell uptime, and inevitably have downtime. Setting the expectation of “always up” and then failing is where disappointment for a customer sets in. How is a regular customer supposed to know it’s impossible? And at the same time, how can a host compete by saying, “We’ve got downtime, just like everybody else!” without losing business? Especially when the standards is to toss in all those 9s for % uptime.
Perhaps a little question mark to explain what 99.9% vs 99.99% uptime means (like hours down per month/year) would benefit, along with a link to an educational article like this, so that customers can be confident that their provider is a leader in the industry, but still fallible.
Without education, 99.9% and especially 99.99% looks like 100% to the average person. So therefore, even hitting a goal of 99.99% is a failure during the 0.01% in the customer’s mind.
I know it’s a catch 22, but maybe a nudge in the right direction, by education on the sales page, can help change expectations, and result in happier customers.
And this couldn’t be more of the truth. It gets even dicier (or at least confusing) when you see things that support a customer’s perspective of 100% uptime, like via ServerBeach’s SLA:
100% Network Uptime
PEER 1 guarantees that the PEER 1 network will be available 100% of the time, excluding Maintenance, as defined below. Customer is eligible for a credit for Network Downtime for any breach of this guarantee, which can be verified by PEER 1’s technical support team. “Network Downtime” is defined as an inability to transmit and receive data caused by failure of network equipment managed and owned by PEER 1, excluding Maintenance, but including managed switches, routers, and cabling.
Or even Pagely’s:
100% Network Uptime
Host guarantees 100% network uptime for our public Internet network, excluding scheduled maintenance. In the event that our network does not experience 100% network uptime in a given month (excluding scheduled maintenance), Host will credit 20% of your monthly service fees for each 3 hours of network downtime experienced up to 100% (for all Service Credits in a given month) of the monthly service fees for those Services affected. Notwithstanding the foregoing, you recognize that the Internet is comprised of thousands upon thousands of autonomous systems that are beyond the control of Host. This SLA and the 100% Network Uptime Service Commitment cover the provision of access by Host to the global internet “cloud”. Routing anomalies, asymmetries, inconsistencies and failures of the Internet outside of the control of Host can and will occur and such instances shall not be considered any failure of the 100% Network Uptime Service Commitment.
100% Infrastructure Uptime
Host guarantees that the critical infrastructure systems will be available 100% of the time in a given month, excluding scheduled maintenance. In the event that critical infrastructure systems do not experience 100% availability in a given month (excluding scheduled maintenance), Host will credit 20% of your monthly fee for each 3 hours of downtime up to 100% (for all Service Credits in a given month) of your monthly fee for those Services affected. Critical infrastructure systems include all power and HVAC infrastructure, including UPSs, PDUs and cabling. Critical infrastructure systems do not include any software or services running on server, nor do they include any server hardware.
Whether you understand this or not and are able to read through the fine-print and understand where the host’s explicit responsibilities start (and end) and how they will qualify coverage and/or reimbursement is one thing – while the rest of the very noobish world will simply see it as a “100% uptime guarantee,” which we know isn’t “true.”
And, not to mention that it can be difficult to even find this type of information to begin with – heck, even WP Engine’s SLA is tough to find and is only available via PDF on a publicly-avaliable Dropbox:
3.2 Service Availability Level Goals. WPEngine shall use reasonable efforts to achieve the target Service Availability Goal of 100% except during scheduled Service Maintenance.
Despite the odd placement and reference link via support at least WP Engine states it fairly well that they shall use reasonable efforts to achieve the target of 100%, which doesn’t mean that they’ll get it, but, hey, they will “try.”
I think WP Engine speaks on behalf of all providers – they are going to do their best, right? For their customers and for themselves, naturally.
But going back to Krogsgard’s comment, the education is still lacking for the most people – what does this mean in plain english? What does this mean in terms of compensation and reimbursement for downtime? What does it mean when:
I can’t connect to my blog but you tell me it’s up and that it’s my internet?
It’s those types of things that provide confusion and ultimately bite the rear of many providers. Sure, my local Comcast or Time Warner connection might fail a few hops away while my managed hosting service is both technically and practically “up” but it still feels like it’s down. And, if I don’t know the wiser, I’m going to blame you!
This is a call for more transparency, greater accountability, and even better education for everyone involved. We shouldn’t have to base our experience or find results of uptime on 3rd party pages, like ServerBear:
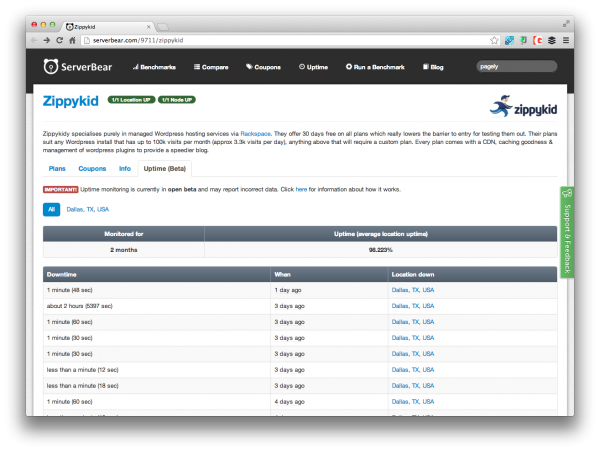
What are your thoughts? Is this just another regurgitation of a long-standing conversation between the customer and the provider and not worth anymore blog posts?
This post has no intention of “calling out” any particular player or citing bad form either – in fact, I believe most of the companies here are doing it right. It’s just a matter of providing that additional level of education that may prove to be helpful for more people.
7 Comments